 Practice lab: Collaborative Filtering Recommender Systems
Practice lab: Collaborative Filtering Recommender Systems
In this exercise, you will implement collaborative filtering to build a recommender system for movies.
 Outline
Outline
Packages 
We will use the now familiar NumPy and Tensorflow Packages.
import numpy as np
import tensorflow as tf
from tensorflow import keras
from recsys_utils import *
1 - Notation¶
| General Notation |
Description | Python (if any) |
|---|---|---|
| $r(i,j)$ | scalar; = 1 if user j rated game i = 0 otherwise | |
| $y(i,j)$ | scalar; = rating given by user j on game i (if r(i,j) = 1 is defined) | |
| $\mathbf{w}^{(j)}$ | vector; parameters for user j | |
| $b^{(j)}$ | scalar; parameter for user j | |
| $\mathbf{x}^{(i)}$ | vector; feature ratings for movie i | |
| $n_u$ | number of users | num_users |
| $n_m$ | number of movies | num_movies |
| $n$ | number of features | num_features |
| $\mathbf{X}$ | matrix of vectors $\mathbf{x}^{(i)}$ | X |
| $\mathbf{W}$ | matrix of vectors $\mathbf{w}^{(j)}$ | W |
| $\mathbf{b}$ | vector of bias parameters $b^{(j)}$ | b |
| $\mathbf{R}$ | matrix of elements $r(i,j)$ | R |
2 - Recommender Systems 
In this lab, you will implement the collaborative filtering learning algorithm and apply it to a dataset of movie ratings. The goal of a collaborative filtering recommender system is to generate two vectors: For each user, a 'parameter vector' that embodies the movie tastes of a user. For each movie, a feature vector of the same size which embodies some description of the movie. The dot product of the two vectors plus the bias term should produce an estimate of the rating the user might give to that movie.
The diagram below details how these vectors are learned.
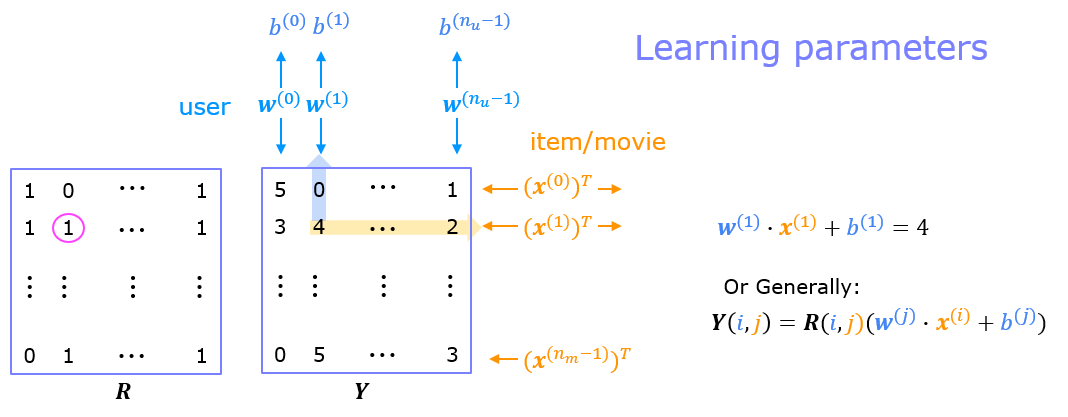
Existing ratings are provided in matrix form as shown. $Y$ contains ratings; 0.5 to 5 inclusive in 0.5 steps. 0 if the movie has not been rated. $R$ has a 1 where movies have been rated. Movies are in rows, users in columns. Each user has a parameter vector $w^{user}$ and bias. Each movie has a feature vector $x^{movie}$. These vectors are simultaneously learned by using the existing user/movie ratings as training data. One training example is shown above: $\mathbf{w}^{(1)} \cdot \mathbf{x}^{(1)} + b^{(1)} = 4$. It is worth noting that the feature vector $x^{movie}$ must satisfy all the users while the user vector $w^{user}$ must satisfy all the movies. This is the source of the name of this approach - all the users collaborate to generate the rating set.
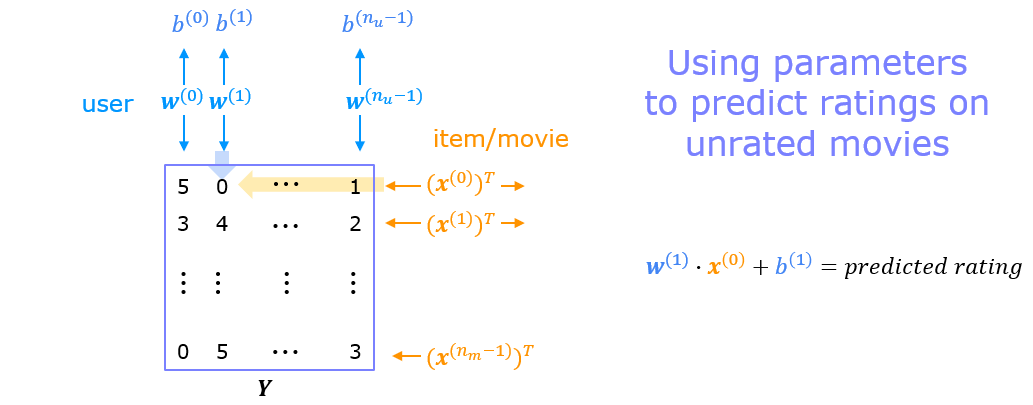
Once the feature vectors and parameters are learned, they can be used to predict how a user might rate an unrated movie. This is shown in the diagram above. The equation is an example of predicting a rating for user one on movie zero.
In this exercise, you will implement the function cofiCostFunc that computes the collaborative filtering
objective function. After implementing the objective function, you will use a TensorFlow custom training loop to learn the parameters for collaborative filtering. The first step is to detail the data set and data structures that will be used in the lab.
3 - Movie ratings dataset
The data set is derived from the MovieLens "ml-latest-small" dataset.
[F. Maxwell Harper and Joseph A. Konstan. 2015. The MovieLens Datasets: History and Context. ACM Transactions on Interactive Intelligent Systems (TiiS) 5, 4: 19:1–19:19. https://doi.org/10.1145/2827872]
The original dataset has 9000 movies rated by 600 users. The dataset has been reduced in size to focus on movies from the years since 2000. This dataset consists of ratings on a scale of 0.5 to 5 in 0.5 step increments. The reduced dataset has $n_u = 443$ users, and $n_m= 4778$ movies.
Below, you will load the movie dataset into the variables $Y$ and $R$.
The matrix $Y$ (a $n_m \times n_u$ matrix) stores the ratings $y^{(i,j)}$. The matrix $R$ is an binary-valued indicator matrix, where $R(i,j) = 1$ if user $j$ gave a rating to movie $i$, and $R(i,j)=0$ otherwise.
Throughout this part of the exercise, you will also be working with the matrices, $\mathbf{X}$, $\mathbf{W}$ and $\mathbf{b}$:
$$\mathbf{X} = \begin{bmatrix} --- (\mathbf{x}^{(0)})^T --- \\ --- (\mathbf{x}^{(1)})^T --- \\ \vdots \\ --- (\mathbf{x}^{(n_m-1)})^T --- \\ \end{bmatrix} , \quad \mathbf{W} = \begin{bmatrix} --- (\mathbf{w}^{(0)})^T --- \\ --- (\mathbf{w}^{(1)})^T --- \\ \vdots \\ --- (\mathbf{w}^{(n_u-1)})^T --- \\ \end{bmatrix},\quad \mathbf{ b} = \begin{bmatrix} b^{(0)} \\ b^{(1)} \\ \vdots \\ b^{(n_u-1)} \\ \end{bmatrix}\quad $$
The $i$-th row of $\mathbf{X}$ corresponds to the feature vector $x^{(i)}$ for the $i$-th movie, and the $j$-th row of $\mathbf{W}$ corresponds to one parameter vector $\mathbf{w}^{(j)}$, for the $j$-th user. Both $x^{(i)}$ and $\mathbf{w}^{(j)}$ are $n$-dimensional vectors. For the purposes of this exercise, you will use $n=10$, and therefore, $\mathbf{x}^{(i)}$ and $\mathbf{w}^{(j)}$ have 10 elements. Correspondingly, $\mathbf{X}$ is a $n_m \times 10$ matrix and $\mathbf{W}$ is a $n_u \times 10$ matrix.
We will start by loading the movie ratings dataset to understand the structure of the data.
We will load $Y$ and $R$ with the movie dataset.
We'll also load $\mathbf{X}$, $\mathbf{W}$, and $\mathbf{b}$ with pre-computed values. These values will be learned later in the lab, but we'll use pre-computed values to develop the cost model.
#Load data
X, W, b, num_movies, num_features, num_users = load_precalc_params_small()
Y, R = load_ratings_small()
print("Y", Y.shape, "R", R.shape)
print("X", X.shape)
print("W", W.shape)
print("b", b.shape)
print("num_features", num_features)
print("num_movies", num_movies)
print("num_users", num_users)
# From the matrix, we can compute statistics like average rating.
tsmean = np.mean(Y[0, R[0, :].astype(bool)])
print(f"Average rating for movie 1 : {tsmean:0.3f} / 5" )
4 - Collaborative filtering learning algorithm 
Now, you will begin implementing the collaborative filtering learning algorithm. You will start by implementing the objective function.
The collaborative filtering algorithm in the setting of movie recommendations considers a set of $n$-dimensional parameter vectors $\mathbf{x}^{(0)},...,\mathbf{x}^{(n_m-1)}$, $\mathbf{w}^{(0)},...,\mathbf{w}^{(n_u-1)}$ and $b^{(0)},...,b^{(n_u-1)}$, where the model predicts the rating for movie $i$ by user $j$ as $y^{(i,j)} = \mathbf{w}^{(j)}\cdot \mathbf{x}^{(i)} + b^{(i)}$ . Given a dataset that consists of a set of ratings produced by some users on some movies, you wish to learn the parameter vectors $\mathbf{x}^{(0)},...,\mathbf{x}^{(n_m-1)}, \mathbf{w}^{(0)},...,\mathbf{w}^{(n_u-1)}$ and $b^{(0)},...,b^{(n_u-1)}$ that produce the best fit (minimizes the squared error).
You will complete the code in cofiCostFunc to compute the cost function for collaborative filtering.
4.1 Collaborative filtering cost function¶
The collaborative filtering cost function is given by $$J({\mathbf{x}^{(0)},...,\mathbf{x}^{(n_m-1)},\mathbf{w}^{(0)},b^{(0)},...,\mathbf{w}^{(n_u-1)},b^{(n_u-1)}})= \frac{1}{2}\sum_{(i,j):r(i,j)=1}(\mathbf{w}^{(j)} \cdot \mathbf{x}^{(i)} + b^{(j)} - y^{(i,j)})^2 +\underbrace{ \frac{\lambda}{2} \sum_{j=0}^{n_u-1}\sum_{k=0}^{n-1}(\mathbf{w}^{(j)}_k)^2 + \frac{\lambda}{2}\sum_{i=0}^{n_m-1}\sum_{k=0}^{n-1}(\mathbf{x}_k^{(i)})^2 }_{regularization} \tag{1}$$ The first summation in (1) is "for all $i$, $j$ where $r(i,j)$ equals $1$" and could be written:
$$ = \frac{1}{2}\sum_{j=0}^{n_u-1} \sum_{i=0}^{n_m-1}r(i,j)*(\mathbf{w}^{(j)} \cdot \mathbf{x}^{(i)} + b^{(j)} - y^{(i,j)})^2 +\text{regularization} $$
You should now write cofiCostFunc (collaborative filtering cost function) to return this cost.
Exercise 1¶
For loop Implementation:
Start by implementing the cost function using for loops.
Consider developing the cost function in two steps. First, develop the cost function without regularization. A test case that does not include regularization is provided below to test your implementation. Once that is working, add regularization and run the tests that include regularization. Note that you should be accumulating the cost for user $j$ and movie $i$ only if $R(i,j) = 1$.
# GRADED FUNCTION: cofi_cost_func
# UNQ_C1
def cofi_cost_func(X, W, b, Y, R, lambda_):
"""
Returns the cost for the content-based filtering
Args:
X (ndarray (num_movies,num_features)): matrix of item features
W (ndarray (num_users,num_features)) : matrix of user parameters
b (ndarray (1, num_users) : vector of user parameters
Y (ndarray (num_movies,num_users) : matrix of user ratings of movies
R (ndarray (num_movies,num_users) : matrix, where R(i, j) = 1 if the i-th movies was rated by the j-th user
lambda_ (float): regularization parameter
Returns:
J (float) : Cost
"""
nm, nu = Y.shape
J = 0
### START CODE HERE ###
### END CODE HERE ###
return J
# Public tests
from public_tests import *
test_cofi_cost_func(cofi_cost_func)
Click for hints
You can structure the code in two for loops similar to the summation in (1). Implement the code without regularization first. Note that some of the elements in (1) are vectors. Use np.dot(). You can also use np.square(). Pay close attention to which elements are indexed by i and which are indexed by j. Don't forget to divide by two.### START CODE HERE ###
for j in range(nu):
for i in range(nm):
### END CODE HERE ###
Click for more hints
Here is some more details. The code below pulls out each element from the matrix before using it.
One could also reference the matrix directly.
This code does not contain regularization.nm,nu = Y.shape
J = 0
### START CODE HERE ###
for j in range(nu):
w = W[j,:]
b_j = b[0,j]
for i in range(nm):
x =
y =
r =
J +=
J = J/2
### END CODE HERE ###
Last Resort (full non-regularized implementation)
nm,nu = Y.shape
J = 0
### START CODE HERE ###
for j in range(nu):
w = W[j,:]
b_j = b[0,j]
for i in range(nm):
x = X[i,:]
y = Y[i,j]
r = R[i,j]
J += np.square(r * (np.dot(w,x) + b_j - y ) )
J = J/2
### END CODE HERE ###
regularization
Regularization just squares each element of the W array and X array and them sums all the squared elements. You can utilize np.square() and np.sum().regularization details
J += lambda_* (np.sum(np.square(W)) + np.sum(np.square(X)))
# Reduce the data set size so that this runs faster
num_users_r = 4
num_movies_r = 5
num_features_r = 3
X_r = X[:num_movies_r, :num_features_r]
W_r = W[:num_users_r, :num_features_r]
b_r = b[0, :num_users_r].reshape(1,-1)
Y_r = Y[:num_movies_r, :num_users_r]
R_r = R[:num_movies_r, :num_users_r]
# Evaluate cost function
J = cofi_cost_func(X_r, W_r, b_r, Y_r, R_r, 0);
print(f"Cost: {J:0.2f}")
Expected Output (lambda = 0):
$13.67$.
# Evaluate cost function with regularization
J = cofi_cost_func(X_r, W_r, b_r, Y_r, R_r, 1.5);
print(f"Cost (with regularization): {J:0.2f}")
Expected Output:
28.09
Vectorized Implementation
It is important to create a vectorized implementation to compute $J$, since it will later be called many times during optimization. The linear algebra utilized is not the focus of this series, so the implementation is provided. If you are an expert in linear algebra, feel free to create your version without referencing the code below.
Run the code below and verify that it produces the same results as the non-vectorized version.
def cofi_cost_func_v(X, W, b, Y, R, lambda_):
"""
Returns the cost for the content-based filtering
Vectorized for speed. Uses tensorflow operations to be compatible with custom training loop.
Args:
X (ndarray (num_movies,num_features)): matrix of item features
W (ndarray (num_users,num_features)) : matrix of user parameters
b (ndarray (1, num_users) : vector of user parameters
Y (ndarray (num_movies,num_users) : matrix of user ratings of movies
R (ndarray (num_movies,num_users) : matrix, where R(i, j) = 1 if the i-th movies was rated by the j-th user
lambda_ (float): regularization parameter
Returns:
J (float) : Cost
"""
j = (tf.linalg.matmul(X, tf.transpose(W)) + b - Y)*R
J = 0.5 * tf.reduce_sum(j**2) + (lambda_/2) * (tf.reduce_sum(X**2) + tf.reduce_sum(W**2))
return J
# Evaluate cost function
J = cofi_cost_func_v(X_r, W_r, b_r, Y_r, R_r, 0);
print(f"Cost: {J:0.2f}")
# Evaluate cost function with regularization
J = cofi_cost_func_v(X_r, W_r, b_r, Y_r, R_r, 1.5);
print(f"Cost (with regularization): {J:0.2f}")
Expected Output:
Cost: 13.67
Cost (with regularization): 28.09
5 - Learning movie recommendations 
After you have finished implementing the collaborative filtering cost function, you can start training your algorithm to make movie recommendations for yourself.
In the cell below, you can enter your own movie choices. The algorithm will then make recommendations for you! We have filled out some values according to our preferences, but after you have things working with our choices, you should change this to match your tastes. A list of all movies in the dataset is in the file movie list.
movieList, movieList_df = load_Movie_List_pd()
my_ratings = np.zeros(num_movies) # Initialize my ratings
# Check the file small_movie_list.csv for id of each movie in our dataset
# For example, Toy Story 3 (2010) has ID 2700, so to rate it "5", you can set
my_ratings[2700] = 5
#Or suppose you did not enjoy Persuasion (2007), you can set
my_ratings[2609] = 2;
# We have selected a few movies we liked / did not like and the ratings we
# gave are as follows:
my_ratings[929] = 5 # Lord of the Rings: The Return of the King, The
my_ratings[246] = 5 # Shrek (2001)
my_ratings[2716] = 3 # Inception
my_ratings[1150] = 5 # Incredibles, The (2004)
my_ratings[382] = 2 # Amelie (Fabuleux destin d'Amélie Poulain, Le)
my_ratings[366] = 5 # Harry Potter and the Sorcerer's Stone (a.k.a. Harry Potter and the Philosopher's Stone) (2001)
my_ratings[622] = 5 # Harry Potter and the Chamber of Secrets (2002)
my_ratings[988] = 3 # Eternal Sunshine of the Spotless Mind (2004)
my_ratings[2925] = 1 # Louis Theroux: Law & Disorder (2008)
my_ratings[2937] = 1 # Nothing to Declare (Rien à déclarer)
my_ratings[793] = 5 # Pirates of the Caribbean: The Curse of the Black Pearl (2003)
my_rated = [i for i in range(len(my_ratings)) if my_ratings[i] > 0]
print('\nNew user ratings:\n')
for i in range(len(my_ratings)):
if my_ratings[i] > 0 :
print(f'Rated {my_ratings[i]} for {movieList_df.loc[i,"title"]}');
Now, let's add these reviews to $Y$ and $R$ and normalize the ratings.
# Reload ratings and add new ratings
Y, R = load_ratings_small()
Y = np.c_[my_ratings, Y]
R = np.c_[(my_ratings != 0).astype(int), R]
# Normalize the Dataset
Ynorm, Ymean = normalizeRatings(Y, R)
Let's prepare to train the model. Initialize the parameters and select the Adam optimizer.
# Useful Values
num_movies, num_users = Y.shape
num_features = 100
# Set Initial Parameters (W, X), use tf.Variable to track these variables
tf.random.set_seed(1234) # for consistent results
W = tf.Variable(tf.random.normal((num_users, num_features),dtype=tf.float64), name='W')
X = tf.Variable(tf.random.normal((num_movies, num_features),dtype=tf.float64), name='X')
b = tf.Variable(tf.random.normal((1, num_users), dtype=tf.float64), name='b')
# Instantiate an optimizer.
optimizer = keras.optimizers.Adam(learning_rate=1e-1)
Let's now train the collaborative filtering model. This will learn the parameters $\mathbf{X}$, $\mathbf{W}$, and $\mathbf{b}$.
The operations involved in learning $w$, $b$, and $x$ simultaneously do not fall into the typical 'layers' offered in the TensorFlow neural network package. Consequently, the flow used in Course 2: Model, Compile(), Fit(), Predict(), are not directly applicable. Instead, we can use a custom training loop.
Recall from earlier labs the steps of gradient descent.
- repeat until convergence:
- compute forward pass
- compute the derivatives of the loss relative to parameters
- update the parameters using the learning rate and the computed derivatives
TensorFlow has the marvelous capability of calculating the derivatives for you. This is shown below. Within the tf.GradientTape() section, operations on Tensorflow Variables are tracked. When tape.gradient() is later called, it will return the gradient of the loss relative to the tracked variables. The gradients can then be applied to the parameters using an optimizer.
This is a very brief introduction to a useful feature of TensorFlow and other machine learning frameworks. Further information can be found by investigating "custom training loops" within the framework of interest.
iterations = 200
lambda_ = 1
for iter in range(iterations):
# Use TensorFlow’s GradientTape
# to record the operations used to compute the cost
with tf.GradientTape() as tape:
# Compute the cost (forward pass included in cost)
cost_value = cofi_cost_func_v(X, W, b, Ynorm, R, lambda_)
# Use the gradient tape to automatically retrieve
# the gradients of the trainable variables with respect to the loss
grads = tape.gradient( cost_value, [X,W,b] )
# Run one step of gradient descent by updating
# the value of the variables to minimize the loss.
optimizer.apply_gradients( zip(grads, [X,W,b]) )
# Log periodically.
if iter % 20 == 0:
print(f"Training loss at iteration {iter}: {cost_value:0.1f}")
6 - Recommendations¶
Below, we compute the ratings for all the movies and users and display the movies that are recommended. These are based on the movies and ratings entered as my_ratings[] above. To predict the rating of movie $i$ for user $j$, you compute $\mathbf{w}^{(j)} \cdot \mathbf{x}^{(i)} + b^{(j)}$. This can be computed for all ratings using matrix multiplication.
# Make a prediction using trained weights and biases
p = np.matmul(X.numpy(), np.transpose(W.numpy())) + b.numpy()
#restore the mean
pm = p + Ymean
my_predictions = pm[:,0]
# sort predictions
ix = tf.argsort(my_predictions, direction='DESCENDING')
for i in range(17):
j = ix[i]
if j not in my_rated:
print(f'Predicting rating {my_predictions[j]:0.2f} for movie {movieList[j]}')
print('\n\nOriginal vs Predicted ratings:\n')
for i in range(len(my_ratings)):
if my_ratings[i] > 0:
print(f'Original {my_ratings[i]}, Predicted {my_predictions[i]:0.2f} for {movieList[i]}')
In practice, additional information can be utilized to enhance our predictions. Above, the predicted ratings for the first few hundred movies lie in a small range. We can augment the above by selecting from those top movies, movies that have high average ratings and movies with more than 20 ratings. This section uses a Pandas data frame which has many handy sorting features.
filter=(movieList_df["number of ratings"] > 20)
movieList_df["pred"] = my_predictions
movieList_df = movieList_df.reindex(columns=["pred", "mean rating", "number of ratings", "title"])
movieList_df.loc[ix[:300]].loc[filter].sort_values("mean rating", ascending=False)
